

Spark:引领大数据处理新篇章,最新迭代版惊艳亮相
在大数据时代,Spark作为一款强大的分布式计算框架,已经成为了业界的热门选择。随着技术的不断进步和市场需求的变化,Spark团队不断迭代更新,推出了一系列功能强大、性能卓越的新版本。本文将带您领略Spark最新迭代版的魅力,探索其在大数据处理领域的无限可能。
一、Spark最新迭代版概览
- Spark 3.0:性能提升与功能优化
Spark 3.0是Spark历史上的一次重大升级,它在性能、功能和易用性方面都取得了显著进步。以下是Spark 3.0的一些亮点:
(1)内存管理优化:Spark 3.0引入了新的内存管理机制,有效提升了内存利用率,降低了内存溢出的风险。
(2)Shuffle性能提升:Shuffle操作是Spark中耗时较长的环节,Spark 3.0通过优化Shuffle算法,显著提高了Shuffle性能。
(3)SQL和DataFrame API性能优化:Spark 3.0对SQL和DataFrame API进行了深度优化,提升了查询性能。
(4)支持JVM外部内存:Spark 3.0支持将数据存储在JVM外部内存中,提高了数据处理能力。
- Spark 3.1:新特性与改进
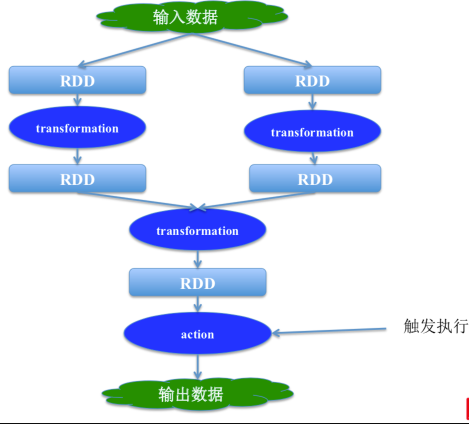
继Spark 3.0之后,Spark 3.1在性能和功能上又有了新的提升。以下是Spark 3.1的一些新特性和改进:
(1)支持Python 3.8:Spark 3.1正式支持Python 3.8,为Python开发者带来了更好的体验。
(2)DataFrame API性能优化:Spark 3.1对DataFrame API进行了进一步的性能优化,提升了数据处理效率。
(3)Tungsten优化:Spark 3.1对Tungsten引擎进行了优化,进一步提升了查询性能。
(4)支持Spark SQL的增量视图:Spark 3.1支持Spark SQL的增量视图,方便用户对数据进行实时监控和分析。
- Spark 3.2:持续优化与创新
Spark 3.2在Spark 3.1的基础上,继续优化性能,引入了新的特性和功能。以下是Spark 3.2的一些亮点:
(1)Shuffle性能提升:Spark 3.2进一步优化了Shuffle算法,提高了Shuffle性能。
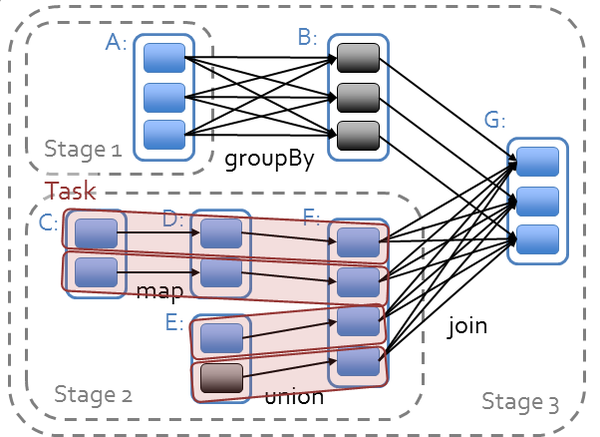
(2)支持分布式SQL查询:Spark 3.2支持分布式SQL查询,使得跨集群的查询更加高效。
(3)DataFrame API性能优化:Spark 3.2对DataFrame API进行了优化,提升了数据处理效率。
(4)支持Spark SQL的增量视图:Spark 3.2继续支持Spark SQL的增量视图,方便用户对数据进行实时监控和分析。
二、Spark最新迭代版的应用场景
Spark最新迭代版在性能和功能上的提升,使得它在各个领域都得到了广泛应用。以下是一些Spark最新迭代版的应用场景:
数据分析:Spark在数据分析领域具有强大的数据处理能力,能够帮助用户快速处理海量数据,挖掘数据价值。
机器学习:Spark MLlib提供了丰富的机器学习算法,方便用户进行数据挖掘和建模。
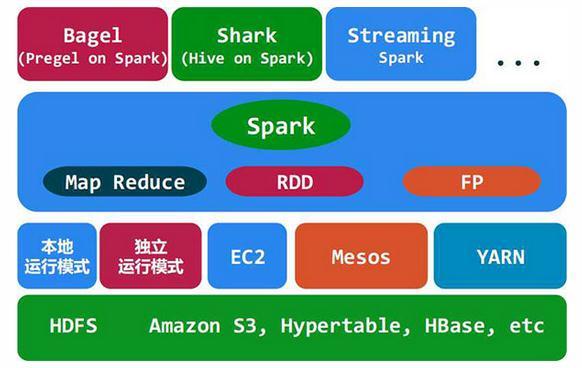
图计算:Spark GraphX是Spark的图计算框架,能够高效处理大规模图数据。
实时计算:Spark Streaming支持实时数据处理,能够满足实时计算的需求。
总结
Spark最新迭代版在性能、功能和易用性方面都取得了显著进步,为大数据处理领域带来了新的活力。随着技术的不断发展,Spark将继续引领大数据处理新篇章,为用户提供更加优质的服务。让我们共同期待Spark在未来的发展,见证其在大数据处理领域的辉煌成就。






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号